InstructSing: High-Fidelity Singing Voice Generation via Instructing Yourself
Abstract
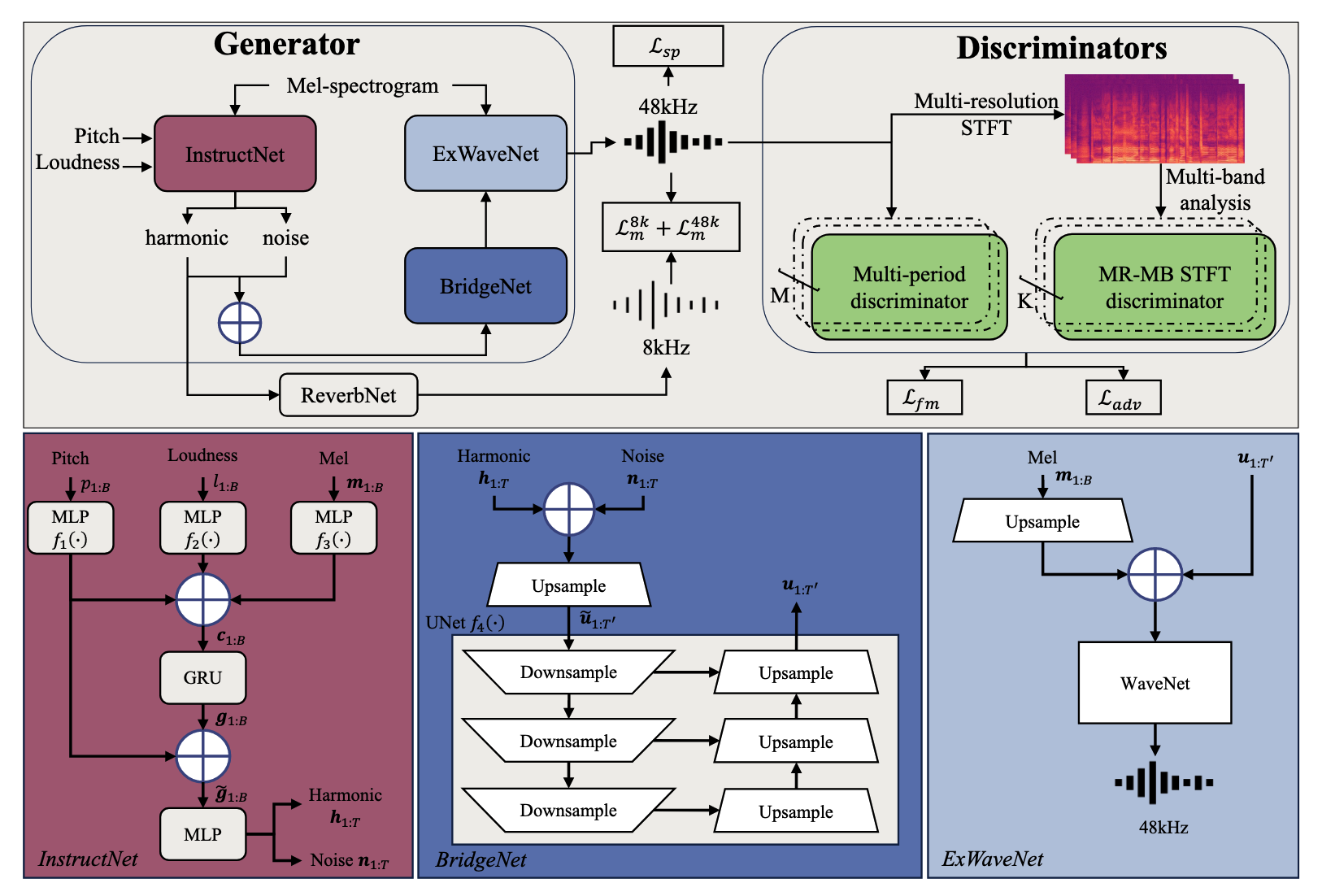
It is challenging to accelerate the training process while ensuring both high-quality generated voices and acceptable inference speed. In this paper, we propose a novel neural vocoder called InstructSing, which can converge much faster compared with other neural vocoders while maintaining good performance by integrating differentiable digital signal processing and adversarial training. It includes one generator and two discriminators. Specifically, the generator incorporates a harmonic-plus-noise (HN) module to produce 8kHz audio as an instructive signal. Subsequently, the HN module is connected with an extended WaveNet by an UNet-based module, which transforms the output of the HN module to a latent variable sequence containing essential periodic and aperiodic information. In addition to the latent sequence, the extended WaveNet also takes the mel-spectrogram as input to generate 48kHz high-fidelity singing voices. In terms of discriminators, we combine a multi-period discriminator, as originally proposed in HiFiGAN, with a multi-resolution multi-band STFT discriminator. Notably, InstructSing achieves comparable voice quality to other neural vocoders but with only one-tenth of the training steps on a 4 NVIDIA V100 GPU machine.
Model Architecture
Audio Samples
All of the spectrogram use same acoustic model.
Audio Quality
变色的生活任性的挑拨 疯狂地冒出了头
GT
InstructSing
HN-UnifiedSourceFilterGAN
RefineGAN
DDSP
风停了也无所谓 只因为你曾说 Everything
GT
InstructSing
HN-UnifiedSourceFilterGAN
RefineGAN
DDSP
我们也不为谁掉眼泪
GT
InstructSing
HN-UnifiedSourceFilterGAN
RefineGAN
DDSP
你有我的蝴蝶
GT
InstructSing
HN-UnifiedSourceFilterGAN
RefineGAN
DDSP
小小的一片云呀 慢慢地走过来 请你们歇歇脚呀
GT
InstructSing
HN-UnifiedSourceFilterGAN
RefineGAN
DDSP
我们走到分叉路口
GT
InstructSing
HN-UnifiedSourceFilterGAN
RefineGAN
DDSP
变成我记忆里的明信片
GT
InstructSing
HN-UnifiedSourceFilterGAN
RefineGAN
DDSP
原来你也在这里啊爱一个人
GT
InstructSing
HN-UnifiedSourceFilterGAN
RefineGAN
DDSP
啊啊哦我为你歌唱
GT
InstructSing
HN-UnifiedSourceFilterGAN
RefineGAN
DDSP
拥抱着夜来香 吻着夜来香
GT
InstructSing
HN-UnifiedSourceFilterGAN
RefineGAN
DDSP
Compare different steps
小小的一片云呀 慢慢地走过来 请你们歇歇脚呀
InstructSing-10ksteps
HN-UnifiedSourceFilterGAN-10ksteps
HN-UnifiedSourceFilterGAN-50ksteps
RefineGAN-10ksteps
RefineGAN-50ksteps
DDSP-10ksteps
DDSP-50ksteps
我们走到分叉路口
InstructSing-10ksteps
HN-UnifiedSourceFilterGAN-10ksteps
HN-UnifiedSourceFilterGAN-50ksteps
RefineGAN-10ksteps
RefineGAN-50ksteps
DDSP-10ksteps
DDSP-50ksteps
变成我记忆里的明信片
InstructSing-10ksteps
HN-UnifiedSourceFilterGAN-10ksteps
HN-UnifiedSourceFilterGAN-50ksteps
RefineGAN-10ksteps
RefineGAN-50ksteps
DDSP-10ksteps
DDSP-50ksteps
原来你也在这里啊爱一个人
InstructSing-10ksteps
HN-UnifiedSourceFilterGAN-10ksteps
HN-UnifiedSourceFilterGAN-50ksteps
RefineGAN-10ksteps
RefineGAN-50ksteps
DDSP-10ksteps
DDSP-50ksteps
啊啊哦我为你歌唱
InstructSing-10ksteps
HN-UnifiedSourceFilterGAN-10ksteps
HN-UnifiedSourceFilterGAN-50ksteps
RefineGAN-10ksteps
RefineGAN-50ksteps
DDSP-10ksteps
DDSP-50ksteps
拥抱着夜来香 吻着夜来香
InstructSing-10ksteps
HN-UnifiedSourceFilterGAN-10ksteps
HN-UnifiedSourceFilterGAN-50ksteps
RefineGAN-10ksteps
RefineGAN-50ksteps
DDSP-10ksteps
DDSP-50ksteps
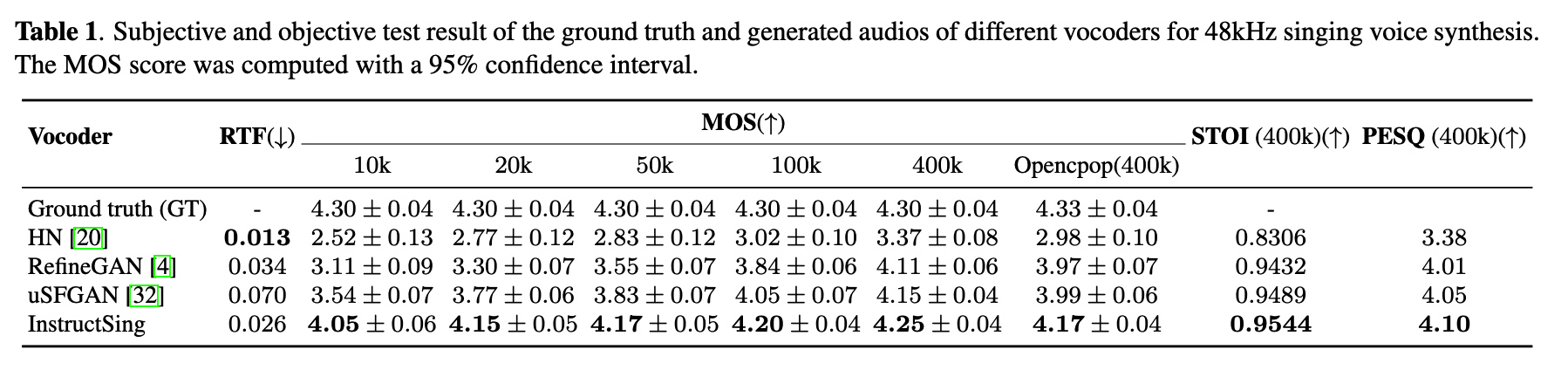
Singing Voice Quality Evaluation
The evaluation experiments are conducted on the server with 12 Intel Xeon CPU, 256GB memory and 1 NVIDIA V100 GPU.
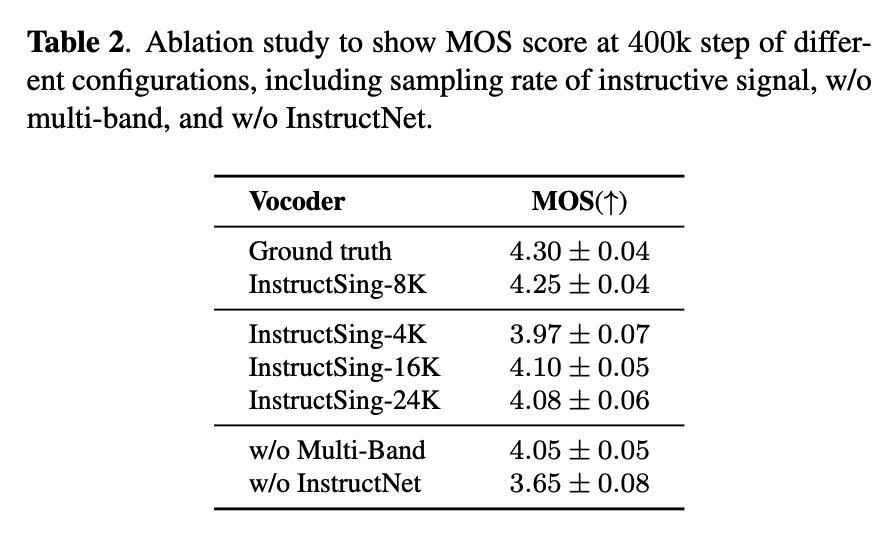
Quality evaluation at different training steps (objective and subjective)
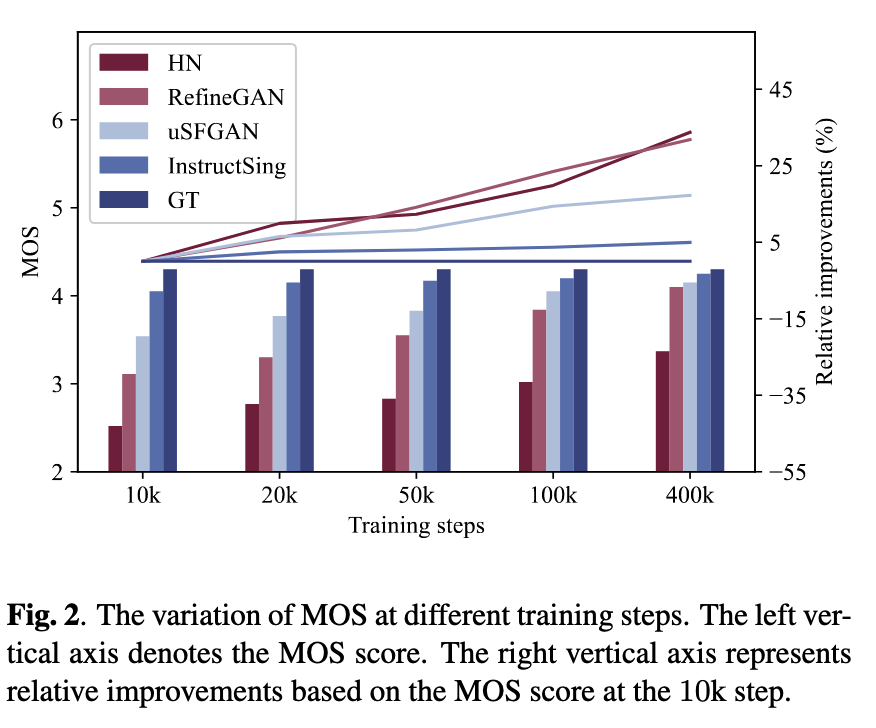
Relative improvement at different steps compared with the score at 10k step